
Sapper, Google Cloud Run, Continuous Deployment - A boilerplate template
Sapper on Cloud Run Architecture
For a while now I have used Sapper / Svelte for my evening and weekend projects and deployed these web applications to Google Cloud Platform.
Source code
A boilerplate repository is available at https://github.com/mootoday/sapper-on-cloud-run. It contains the default Sapper template, scripts to set up Google Cloud Platform, a Dockerfile and a cloudbuild.yaml file you can adjust for your needs.
To get started, click the Use this template button:

What you will learn
In this post, you will:
- Understand what SSR (server-side rendering) and SSG (static site generator) is and what benefits / drawbacks each has.
- Create a Docker image for your SSR Sapper application.
- Deploy that image to Cloud Run, where it runs as a serverless service.
- Create a continuous deployment pipeline to automate the entire process.
The assumption in this post is that you use the Sapper template as documented on the website and started your project with the following commands:
# for Rollup
npx degit "sveltejs/sapper-template#rollup" my-app
# for webpack
npx degit "sveltejs/sapper-template#webpack" my-app
cd my-app
npm installTo start with, let’s discuss SSR vs SSG.
SSR vs SSG with Sapper
There are two main options for the deployment:
- SSR as in server-side rendering
- SSG as in static site generator
Server-side rendering
In this scenario, you use two commands provided by Sapper to run a backend server:
npm run buildnpm start
At a high-level, the first command outputs artifacts to __sapper__/build whereas the second command starts a simple Node.js server located at __sapper__/build/index.js. Static assets are served from the root’s static directory, for example images and other assets you provide.
You can deploy the code to a virtual machine or serverless platform, start the server and the website is up and running.
Benefits
When visitors load your web application for the first time, the server generates the entire page and sends the rendered HTML, JS and CSS to the browser. Subsequent navigation happens client-side. The user experience is better than with frameworks that send an empty <div> element and load the content at runtime as Sapper does not send any runtime framework to the client. It also allows search engines to crawl the website, so SEO (search engine optimization) is provided by default.
Things to consider
You need to manage a server. Whether that is a virtual machine or a serverless offering such as Cloud Run, it is a piece of your architecture that needs to be taken care of.
Static site generator
You may have heard of JAMstack, which stands for JavaScript, APIs, Markup. It’s quite a buzzword nowdays. In this scenario, you use a single command provided by Sapper to export a static version of your web application:
npm run export
There is quite a bit going on as part of this command, so let’s break it down:
- Sapper applies code splitting based on your routes in
src/routesand generates bundles of JavaScript, HTML and CSS. - Sapper starts the web application locally and crawls its content, starting at
/and following each<a>tag. It fetches the data defined in a route’spreloadfunction. - For each route, Sapper generates a static HTML file in
__sapper__/export.
You can deploy the content of __sapper__/export to any hosting platform and serve your static web application.
Benefits
No server is required anymore! All you have is a directory of assets you can deploy, including to CDN (content delivery network) systems to make your web application available in close proximity to a global audience.
This is what the web used to be in the 90s. A bunch of websites that linked to other web pages with an <a> tag. When you click a link, the next page is fetched, fully pre-rendered and ready for the browser to display it. A drawback in the 90s was that for each page load, the entire HTML, CSS, JavaScript had to be downloaded and rendered again.
Sapper has a solution called prefetching. Create your anchor tags like this <a rel="prefetch"> and Sapper will prefetch the link’s URL when the user moves their mouse over the link, even before they click. By the time they do click, Sapper already fetched the content of the upcoming page and instantly displays it.
Things to consider
If you want to make a change to the web application, you need to regenerate it and redeploy. If you have 30,000 pages, that will take some time and is likely not feasible. The solution: Incremental builds. If you add a new page or update an existing one, only that page should be exported and deployed. At the time of this writing, incremental builds do not exist in Sapper.
The other consideration is dynamic content, such as when users need to be authenticated. In this case, it is not possible to generate pages for each user and we need a solution that provides SSR.
Deploy a Sapper SSR web application to Cloud Run with continuous deployment
Let’s see how we can use the SSR approach, but make sure we have minimal work to do with the server that runs the Sapper application.
The overall architecture we are going to create looks like this:
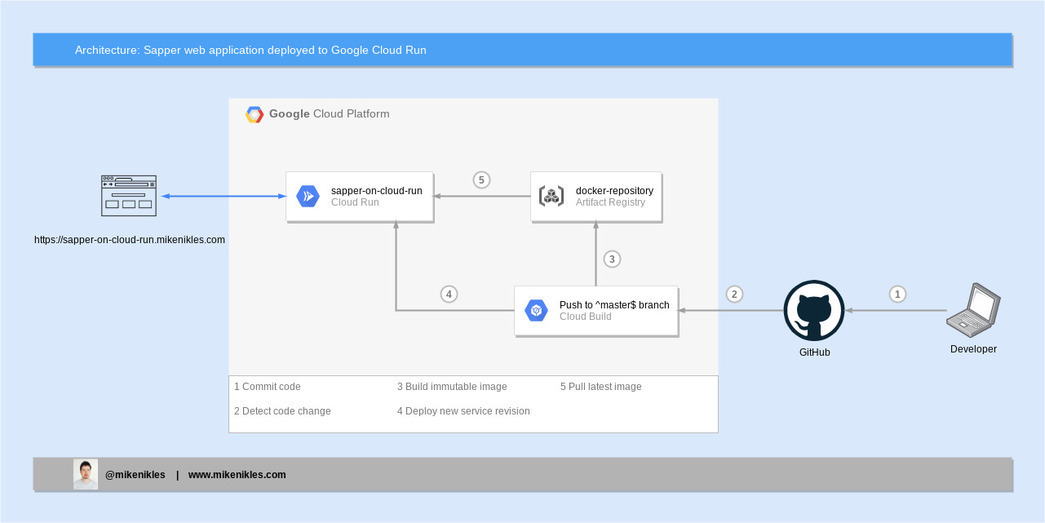
Continuous Deployment of a Sapper web application to Cloud Run
The diagram shows two aspects; one being the end user on the left who visits a Sapper SSR web application. The other being a developer on the right who makes a code change, opens a pull request and gets that merged into the master branch.
Containerize the Sapper application (Pull Request)
The first step is to create a Dockerfile. The aim is to keep the final size of the Docker image as small and as lean as possible.
# This stage builds the sapper application.
FROM mhart/alpine-node:12 AS build-app
WORKDIR /app
COPY . .
RUN npm install --no-audit --unsafe-perm
RUN npm run buildWhat’s going on here? Let’s review:
- We start with a Node.js 12 base image and name this stage
build-app. - We specify the working directory as
/app. - The
COPYcommand copies everything from the local file system where theDockerfileis located to the current working directory inside the image. This is set to /app in step 2 above.
Note: To build the web application, we don’t really need to copy “everything”. So we will create a.dockerignorefile shortly to define what to copy and what to ignore. - Install dependencies, this includes
devDependencies. The--no-auditflag speeds up the process as it does not perform security audits of the packages.
Note: The--unsafe-permflag is needed because the Docker build process builds the image as the root user. - Build the web application. By default, the output is in the
__sapper__directory relative to thepackage.jsonfile.
In the next stage, we install the runtime dependencies. In the Dockerfile, copy the following content below what you copied earlier:
# This stage installs the runtime dependencies.
FROM mhart/alpine-node:12 AS build-runtime
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm ci --production --unsafe-permAll we need for this stage is the package*.json files. Then we use the npm ci command to install production dependencies.
The third and final stage in the Dockerfile is where we create the runtime image.
Add the following to the end of the Dockerfile:
# This stage only needs the compiled Sapper application
# and the runtime dependencies.
FROM mhart/alpine-node:slim-12
WORKDIR /app
COPY /app/__sapper__ ./__sapper__
COPY /app/static ./static
COPY /app/node_modules ./node_modulesLet’s review this in detail too:
- You may have noticed the slight change to the based image, did you? At runtime, we don’t need NPM (which is pre-installed on the base images we used in stages
build-appandbuild-runtime). We can use theslim-12tag of themhart/alpine-nodeimage to achieve this. - As before, we set the working directory to
/app. - Copy the compiled Sapper app from the
build-appstage. - Copy the static assets from the
build-appstage. - Copy the runtime dependencies from the
build-runtimestage.
To wrap up, we need to add two more lines at the bottom of the Dockerfile:
EXPOSE 3000
CMD ["node", "__sapper__/build"]Sapper runs listens on port 3000 once the Docker image is used to spin up a container, so we expose that port.
Lastly, we define how to start the Sapper application.
If you were to build an image based on the instructions in the Dockerfile now, you would end up with a final image size of 47.1MB. In the COPY . . at the top of the file, we copy the entire content and all sub-directories. We can avoid that with a .dockerignore file:
/*
!/package.json
!/package-lock.json
!/rollup.config.js
!/src
!/staticLet me explain my approach. The first line ignores everything. Then I selectively define what not (!) to ignore. It sounds a bit complex, but hear me out. The alternative would be to ignore what is not needed in the Docker image. The .dockerignore file would look something like this:
cypress
node_modules
LICENSE
README.md
cypress.jsonAs the project grows and more team members join, someone at some point inevitably will add files or new directories. With the second approach, these new files and directories would need to be added to the .dockerignore file. What are the chances this will happen ;-)?!
With the the .dockerignore file in place, the final docker image size is 46.9MB. A small difference, but it will forever include only exactly what the Sapper application needs and never accidentally any unnecessary files or directories.
Deploy to Cloud Run (Pull Request)
Alright, we have a Dockerfile in place, which is a key milestone in getting the Sapper web application deployed to Cloud Run.
We have two steps left:
- Deploy that image to Cloud Run, where it runs as a serverless service.
- Create a continuous deployment pipeline to automate the entire process.
To achieve this, we will flip the steps and start with developing the continuous deployment process, which will then deploy to Cloud Run.
We need a place to store the Docker image. This is referred to as a registry and the likely most well known one is Docker Hub at https://hub.docker.com. Given we want to deploy to Cloud Run on Google Cloud Platform (GCP), it makes sense to use services that are in close proximity to each other. We have two options at the moment:
- Container Registry
- Artifact Registry (in beta as of spring 2020)
Let’s use Artifact Registry as its website states “The next generation of Container Registry”. We need to create a repository first:
# Enable the Artifact Registry API
gcloud services enable artifactregistry.googleapis.com
# Create an Artifact Registry repository to host docker images
gcloud beta artifacts repositories create docker-repository --repository-format=docker
--location=us-central1Next, we are going to use Cloud Build, it is a service provided by Google Cloud Platform. Alternatives exist with Jenkins, GitHub Actions, GitLab Pipelines, CircleCI, etc.
Let’s start with a new cloudbuild.yaml configuration file. In the file, we are going to define a set of steps Cloud Build will execute:
steps:
# build the container image
- name: 'gcr.io/cloud-builders/docker'
args:
[
'build',
'-t',
'us-central1-docker.pkg.dev/$PROJECT_ID/docker-repository/sapper-on-cloud-run:$COMMIT_SHA',
'.'
]We define a name of a builder, this can be any Docker image. In this case, we use a builder that has docker installed. The args are the same arguments you would pass to the docker command locally. The tag (-t) argument defines the Artifact Registry repository we created earlier, plus the name of the image and a tag, in our case $COMMIT_SHA. This variable is provided by Cloud Build at runtime and makes sure images are identifiable with their corresponding git commit SHA.
With the docker image built, we need to push it to the registry:
# push the container image to Artifact Registry
- name: 'gcr.io/cloud-builders/docker'
args:
[
'push',
'us-central1-docker.pkg.dev/$PROJECT_ID/docker-repository/sapper-on-cloud-run:$COMMIT_SHA'
]Lastly, we can tell Cloud Run that the image is available and a new revision of the service can be deployed:
# Deploy container image to Cloud Run
- name: 'gcr.io/cloud-builders/gcloud'
args:
- 'run'
- 'deploy'
- 'sapper-on-cloud-run'
- '--image'
- 'us-central1-docker.pkg.dev/$PROJECT_ID/docker-repository/sapper-on-cloud-run:$COMMIT_SHA'
- '--region'
- 'us-central1'
- '--platform'
- 'managed'
- '--allow-unauthenticated'
images:
- 'us-central1-docker.pkg.dev/$PROJECT_ID/docker-repository/sapper-on-cloud-run:$COMMIT_SHA'Before we submit this file and deploy the first version of the web application, we need to set up Cloud Build and Cloud Run.
Create a Cloud Build trigger
We want the deployment to happen automatically for each code change on the master branch in GitHub. The following commands enable the Cloud Build API and configure the trigger:
# Enable the Cloud Build API
gcloud services enable cloudbuild.googleapis.com
# Create a build trigger
gcloud beta builds triggers create github
--repo-name=sapper-on-cloud-run
--repo-owner=mootoday
--branch-pattern="^master$"
--build-config=cloudbuild.yamlTo make this integration work, you also have to configure the Cloud Build GitHub app.
Set up Cloud Run and grant permissions to Cloud Build
Finally, we have to allow Cloud Build to deploy the web application to Cloud Run:
# Obtain the numeric project ID
# Use: gcloud projects list --filter="$(gcloud config get-value project)" --format="value(PROJECT_NUMBER)"
# Grant the Cloud Run Admin role
gcloud projects add-iam-policy-binding $PROJECT_ID
--member "serviceAccount:[email protected]"
--role roles/run.admin
# Grant access to Cloud Build to deploy to Cloud Run
gcloud iam service-accounts add-iam-policy-binding
[email protected]
--member="[email protected]"
--role="roles/iam.serviceAccountUser"Map a custom domain
Every time a new revision of the web application is deployed to Cloud Run, a new URL is created. You can configure traffic splitting to do canary releases etc. In a production environment, you need a custom domain mapped and this can be done with a single command:
gcloud beta run domain-mappings create
--service sapper-on-cloud-run
--domain sapper-on-cloud-run.mootoday.com
--region us-central1
--platform managedNote: This command only works once you verified the domain. Details on how to verify a domain can be found in the documentation.
Conclusion
Once all files are committed and pushed to the master branch, Cloud Build takes the latest code, builds a Docker image, pushes it to the Artifact Registry and instructs Cloud Run to deploy a new revision with the latest image.
There is a lot more to this architecture, such as traffic splitting, rollbacks, etc we may look at in a later post.
👋